RECRUIT 日本橋ハーフマラソン 2023夏(AtCoder Heuristic Contest 022)に参加しました。
結果は15位でした。頑張ったぞー
コンテストページ
解法
いろいろやりましたが全部書くと大変なので、特に良くできたと思ってる推定部分だけ書きます。
※数学的に正しいかどうかはかなり怪しいです
誤差について
計測時の誤差は平均0、標準偏差Sの正規分布であると問題に書かれています。
正規分布の累積分布関数を使うことで、誤差の値からそれが発生する確率を求めることができます。
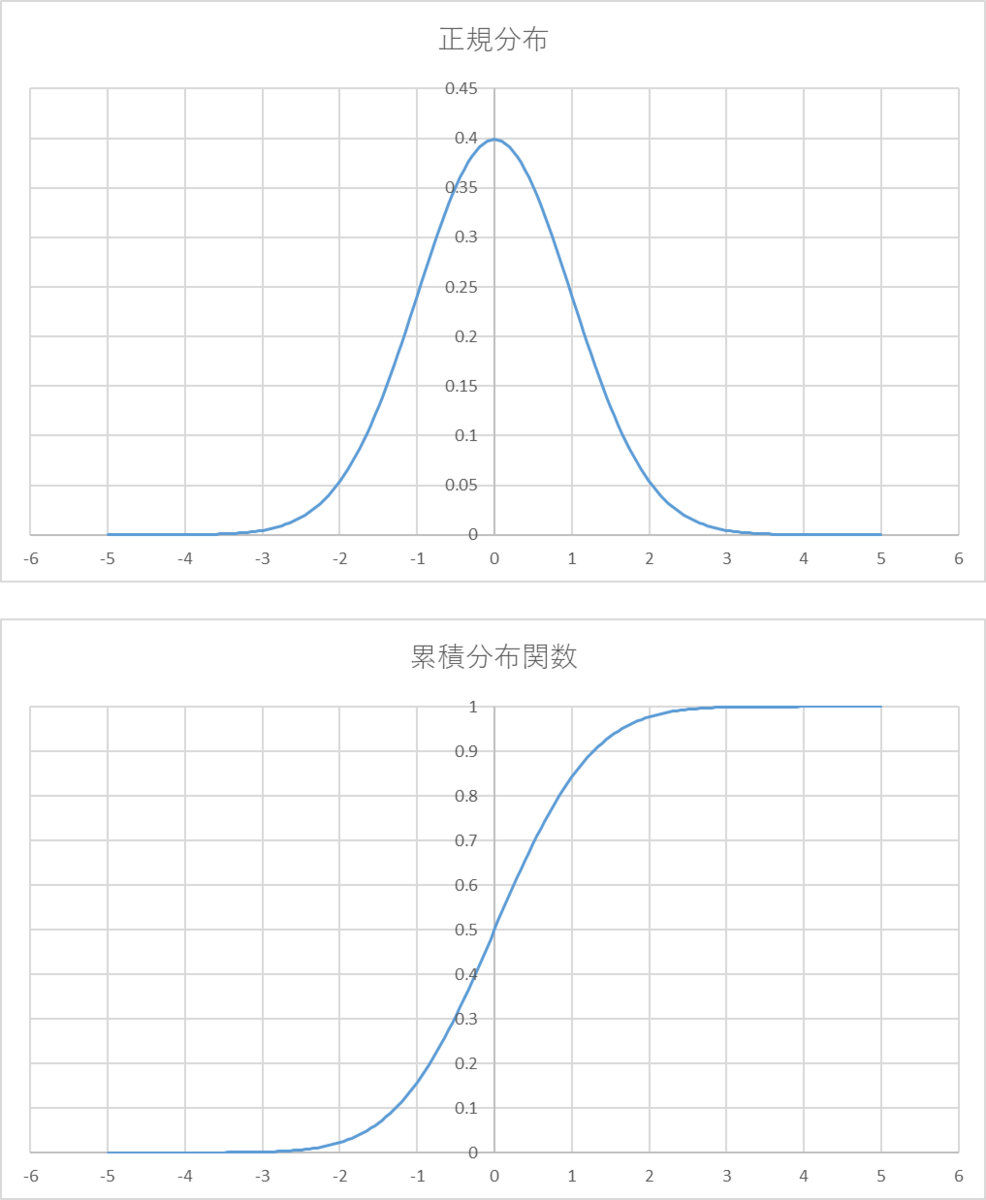
累積分布関数をf(x)とすると、f(x)はx以下の値が発生する確率を表しています。
f(b) - f(a) とすれば、値がa~bの範囲内になる確率を計算できます。(累積和みたいなもの)
式は以下のようになります。(※今回の問題に合わせて平均0標準偏差Sとして整理したものです。一般的な式はwikiなどを見てください。)
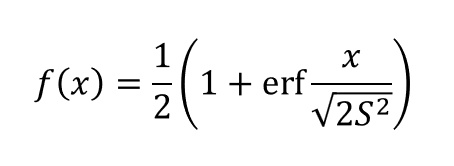
erfというのは誤差関数というものらしいです。C++にerfを計算する関数が用意されていたのでそれを使いました。
例えばS=1の時、温度が100である出口を調べて101が取得されたなら、四捨五入を考慮すると発生した誤差は+0.5~+1.5の範囲です。
この誤差が発生する確率はf(1.5) - f(0.5)=0.2417...つまり24%ぐらいのことが起こったことになります。
もう一つ例、S=900の時、温度が500である出口を調べて1000が取得されたら、発生した誤差は+499.5~+∞の範囲と言えます。累積分布関数には無限大を入れることもできて、f(∞) - f(499.5)=0.2894...つまり29%ぐらいのことが起こったと計算できます。
推定方法
各入口が各出口につながっている確率の表を作り、計測のたびに表を更新していきます。
説明のために入口と出口がそれぞれ3つのケースで考えます。S=625とします。
まず表の初期状態はすべて等確率にします。
入口Aを移動(0,0)で計測した結果、温度400が取得されました。
移動(0,0)の場合、各出口につながっているとした場合の温度は次のようになっているとします。
- 出口a: 0
- 出口b: 500
- 出口c: 1000
入口Aと出口aがつながっているとすると、温度0のものが400として取得されたということなので、発生した誤差は399.5~400.5になります。この誤差が発生する確率は0.0005201..となります。
他の出口も同様に計算すると
- 出口a: 0.0005201
- 出口b: 0.000630189
- 出口c: 0.000402631
となります。
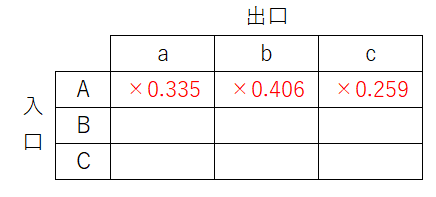
必ずどれかの出口につながっているはずなので、合計が1になるように正規化(全要素の合計値で各要素を割る)します。すると
- 出口a: 0.335...
- 出口b: 0.406...
- 出口c: 0.259...
となりました。
この値は、入口Aが各出口とつながっていた時に温度400という出来事がどれだけ起こりやすいかを表しています。(尤度と言います。確率ではないはず?)
厳密には確率値ではないのだと思いますが、合計が1になるようにしてあるのでこれ以降は確率と呼んでしまいます。よって、今回の計測結果だけを見ると入口Aは出口bにつながっている確率が40.6%だったといえます。
得られた確率値を使って表の更新を考えます。
まず計測した入口Aに関しては今得られた値をそのまま乗算します。
計測しなかった入口B,Cにも影響があるはずです。例えば入口Aが出口aとつながっている確率が高いと算出されたなら、入り口Bが出口aとつながっている確率は下がるはずです。
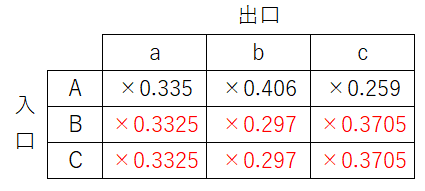
これを表現するために、出口側から見たときの合計が1になるように他の入口にも分配するような形にしました。
出口aから見ると入口のどれかに必ずつながっています。出口aが入口Aに0.335の確率でつながっているとするなら、それ以外の入口につながっている確率は1-0.335=0.665、それ以外の入口は2個あるので等分して、0.665/2=0.3325となります。
同様に他の出口でも行うと、以下のように表を更新することに決まりました。
元の表にこの更新を掛けると
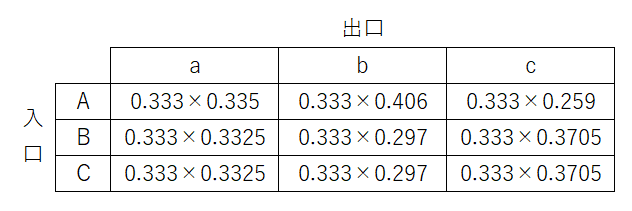
となり
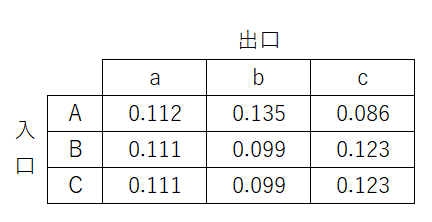
上記のようになりました。
この計算を行うと横方向の合計が1にならなくなるため、行ごとに合計値が1になるように正規化をします。(正規化しないと数値がどんどん小さくなっていき、プログラム上で表現できなくなり0になってしまう、という問題もあります。)
正規化した結果が以下の表です。
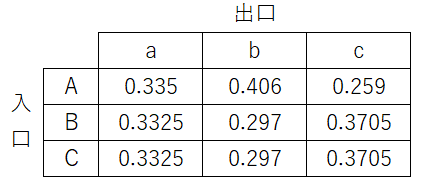
横方向の正規化により、入口がどの出口に対応するかの確率値としては見れますが、出口側から見てどの入り口に対応するかという確率値としては見れなくなります。
そのため、入口Aが出口bにつながる確率が90%で入口Bも出口bにつながる確率が90%のような、複数の入り口が同じ出口につながってしまう状態が発生します。この状態は必ず間違っているため、この状態が解消されるまでは回答を出力しないようにし、間違いを識別するための計測を優先的に行うようにしてました。
ここまでが1回の測定結果を受けての表の更新の流れです。これを計測のたびに行い、表を更新してきます。繰り返していくとだんだん正解の入口出口の組み合わせの確率が上がっていきます。
全ての入口と出口の確率が一定以上になったら計測を終了し、回答を出力します。
表が更新されていく様子の可視化
縦がワームホール、横が出口の確率行列を更新していく様子。#AHC022 #rcl_procon pic.twitter.com/RoCct6dXks
— bowwowforeach (@bowwowforeach) 2023年8月20日
コンテスト後に知ったこと
横方向を正規化するところで、縦方向にも正規化をすると良いらしいです。
これを行うと複数の入口が同じ出口につながることが自然になくなります。実際にやってみたらスコアも結構上がりました。
また、出口側から入口につながる確率もおそらく使えるようになるので、高温に近い出口を優先して調べるといったことも可能になりそうです。まだまだできることはあったんだなあ。
以上、推定って難しい!