トヨタ自動車プログラミングコンテスト2024#5(AtCoder Heuristic Contest 033)参加記
トヨタ自動車プログラミングコンテスト2024#5(AtCoder Heuristic Contest 033)に参加して優勝しましたー
自分の解法を解説します。
問題
複数のクレーンを操作して、すべてのコンテナをできるだけ早く搬出しよう。
詳細は問題ページを見てください。
初めに
問題文では「コンテナ」となっていますが、ここでは「箱」と表記します。
基本方針
- 一時置き回数を最小化するような搬入順序をDPで求める
- クレーンの移動経路は縦x横x時間の3次元グリッド上でBFSの要領で求める
- タスクをクレーンに割り当てる問題と考え、割り当て方をビームサーチで探索
これらの方針は公式解説でされているものと同じです。
すごくわかりやすく解説されていますので、先に公式解説を見ることをお勧めします。
本記事では、公式解説で話されていない内容を中心に書きます。
重複状態の除去
タスクを割り当て方を決めるビームサーチでは、割り当ての順序が違っても結果的に同じ割り当てになるケースがあります。
例えば、タスクAとタスクB、クレーン1とクレーン2があるとき
・タスクAをクレーン1に割り当て、次にタスクBをクレーン2に割り当てる
・タスクBをクレーン2に割り当て、次にタスクAをクレーン1に割り当てる
これらは順序は違えどクレーンに割り当たったタスクは同じです。
違うのは経路で、先に割り当てたクレーンが先に動き、後に割り当てたクレーンは先のクレーンを避けた経路になります。避けるなどの無駄な移動が発生した場合はタスク完了にかかるターン数が伸びているので評価値が悪くなります。
この場合は同じ状態とみなして、評価値が悪いほうは見込みがないものとして捨ててしまいます。
同じ状態と判定する方法は、クレーンの位置と各番号の箱がどこに置いてあるかでZobristHash化して、ハッシュ値の一致で重複と判定しました。
ハッシュ化する際に、大クレーンと小クレーンは区別する必要がありますが、小クレーン同士は位置関係が変わっても同じなので区別しないようにします。
高速な経路探索
今回の問題は5x5と盤面が小さいので、ビットボードが使えます。
以下のように各セルに番号を振ります。

32bitの変数1個で各場所にクレーンがあるかなどを表現できます。
例えば、2と13の位置にクレーンがいる状態は2bit目と13bit目(0-indexed)が1でそれ以外のbitが0として表せます。
クレーンの位置がビットボードに記録されているとき、ビットボードを右に1bitシフトすると、クレーンの位置が左に1マス動いたことになります。右に6bitシフトすると上に1マス動いたことになります。同様に左に1bitシフトは右に1マス、左に6bitシフトは下に1マス動いたことになります。
グリッドの左端の例えば12の位置にいるときに、左に1マス移動である1bit右シフトをすると11になります。このような不正な移動を除外するためにダミー列を追加しています。
これらの性質を使うと、経路探索時の「あるターンに到着可能な場所から、次のターンの到着可能な場所を求める」部分がビット演算で高速に計算できます。
以下はある場所から目的地に着くまでの最短ターンを計算するサンプルコードです。
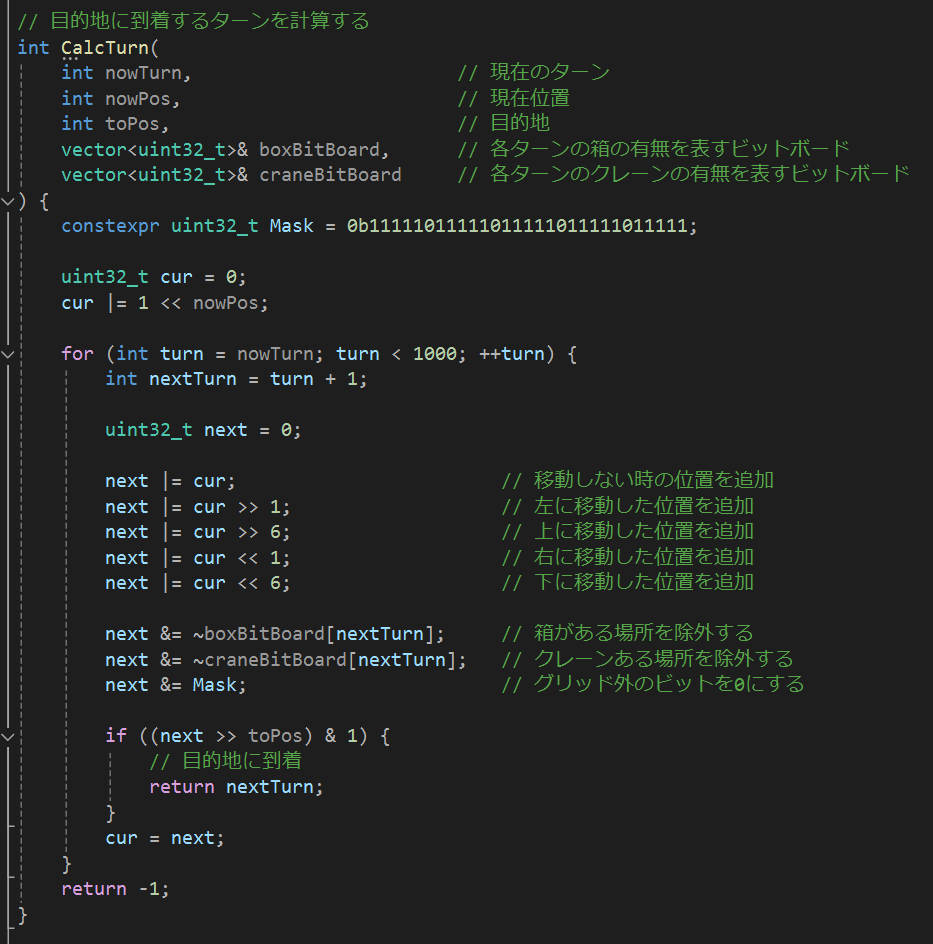
このサンプルコードではクレーンのすれ違いを考慮していません。少し工夫すれば対応できます。
経路の復元は、目的地に到着するターンを計算するときに出た、各ターンの到着可能な場所ビットボードをとっておいて、目的地側から前のターンにどこにいたかを遡るようにして辿れば復元できます。
一時置き回数が最小でない順序も許容する
一時置き回数最小の搬入順序だと、同じ行からの搬入が続いたときにいくつかのクレーンが待たされてしまうことがあります。待たされるぐらいなら一時的に置いてもよいので少しでも搬出口に近づくように運んでおいた方が、トータルのターン数は減らせるというケースがあるようです。(他の理由もあるかもしれません)
例えばseed=38は一時置き回数0が達成できます。一時置きを禁止すると65ターンかかり、一時置きを許容すると3回の一時置きをして60ターンで済みました。
許容するといっても一時置き回数が多いこと自体はやはりロスになるので、最適解の順序からあまり離れすぎないように制限しました。
評価値
以下を評価値として使いました。
・搬入した箱の総数
・行ごとの搬入数
・搬出した箱の総数
・行ごとの搬出数
・一時置きされている箱の場所(一時置き場所候補3x5=15セルそれぞれで違う重み)
・クレーンごとのタスクが完了するターン数
・全クレーンのタスクが完了するターン数
・箱を拾いに行くときのターン数のロス(マンハッタン距離との差)
・箱を運ぶときのターン数のロス(マンハッタン距離との差)
・一時置きした回数
・一時置き最小回数の搬入手順からどれだけ外れたか
・拾うための移動にかかった総ターン数
・運ぶための移動にかかった総ターン数
評価値調整法
あまりお勧めできる方法ではありませんが、自分のやってる評価値調整法を書いてみます。
・評価値として使えそうなものを出します。
・大きいほうがいいのか小さいほうがいいのかで符号を決めます。
・線形なのか指数なのかなど、関数の形を決めます。
・評価値に重みを付けて足し込みます(ものによっては掛けたり割ったりも)
・たくさんのテストケースを回してみて、スコアが上がるように重みを手動調整します。
・スコアが上がりそうなら採用。下がるなら不採用。怪しいならOptunaでちょっと調整して判断。
・こんな感じでどんどん追加していきます。
・コンテスト終盤にOptunaでまとめて調整します。
理詰めで考えるのは苦手なので、とにかくいろんなことを試すように心がけています。
枝刈り
高速化や不要な割り当てを防ぐために、タスク割り当てに次の条件を課しました。
・搬出可能な箱は一時置きしない
・各箱につき一時置きは1回まで
・一時置き場所、現在の置き場所よりも搬出口に近づかなければならない
・5行のうち1行は中心3列に箱を1つも置かない
・タスク完了ターンが最大のクレーンには割り当てない
・タスク完了ターン最小のクレーンのターン数よりも、そのクレーンのタスク完了ターン数が一定以上大きければそのクレーンに割り当てない
・タスク完了までの最短ターン(マンハッタン距離で算出)よりもが一定以上遅れるなら割り当てない
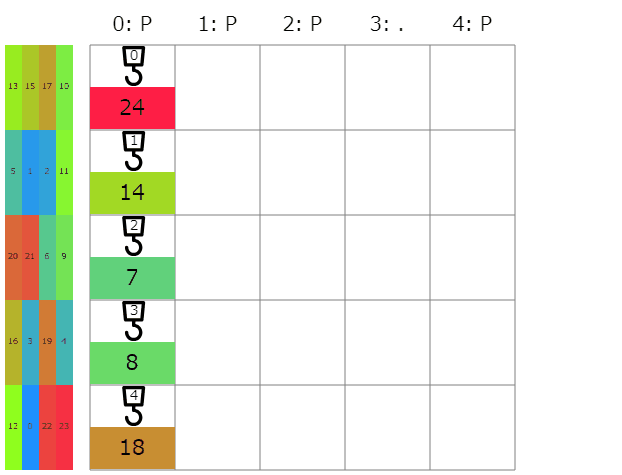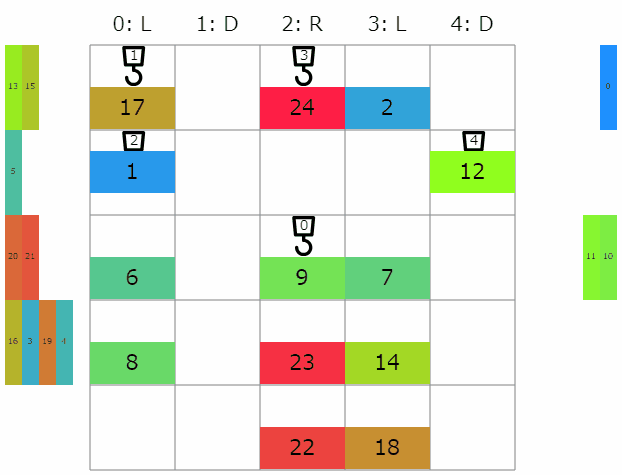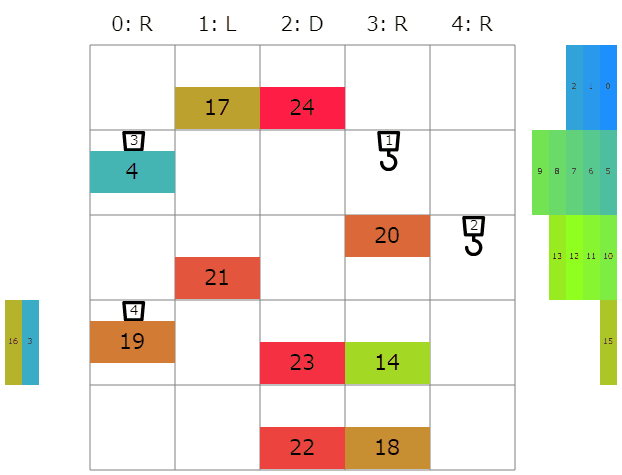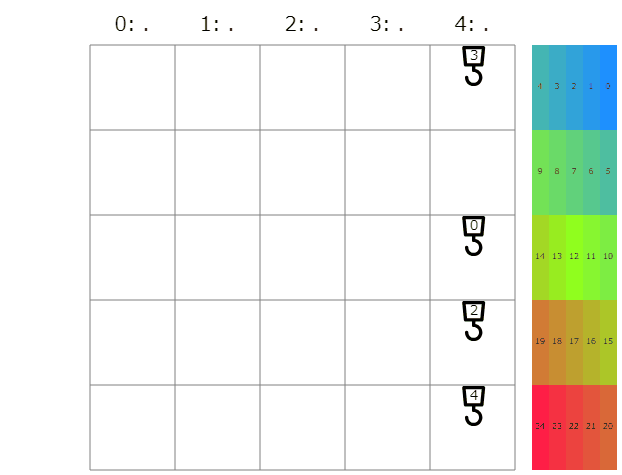
ビジュアライザ
seed=0 Score=66
感想など
・時間を含めた3次元上で経路探索することを思いついて、これすごい発見だと思ったのですが結構みんな思いついてそうですね……アルゴりょくぅ?
・これだという解法に早めにたどり着けたのが良かったです。そのぶん高速化とパラメータ調整に時間をかけることができました。でも最終日は何試してもスコアが上がらず苦しかったです。
・固定長配列大スキーなので入力サイズ固定なのはうれしい!ビットボードも使えてうれしい!
以上、ありがとうございましたー
MC Digital プログラミングコンテスト2024(AtCoder Heuristic Contest 031)参加記
MC Digital プログラミングコンテスト2024(AtCoder Heuristic Contest 031)に参加しました。結果は4位でした!
コンテストページ
解法
主に3つの解法を使いました
①コスト0狙いの2分割貪欲
②短冊状に分けて、短冊内の区切り線を焼きなまし
まず①でコスト0の解を探索し見つかれば終了。
次に、何個の短冊に分けられるかを計算します。2個以上の短冊に分けられるなら②の解法を使い、そうでないなら③の解法を使います。
①コスト0狙いの2分割貪欲
全ての日の予約を1日分にまとめます。(k番目の予約ごとに全ての日のmaxサイズをとる)これで1日分のN個の予約を割り当てる問題になります。
N個の予約を面積合計ができるだけ同じになるように2つのグループに分けます。(予約を面積大きい順にソートして小さいグループに割り当ててく貪欲)
そして、グループの面積比で区画を2つに分けます。
それぞれの区画を同様に再帰的に分けていき、グループ内の予約数が1個になったらその予約に対応する区画が決定します。
すべての予約の面積を満たせるならコスト0の解が見つかったということになります。
※この解法はコスト0にできるケースで確実に解を見つけられるわけではありません。
何個の短冊に分けられるか
短冊数を仮に決めて、それが予約面積を満たせるかどうかを判定することで二分探索的に決めました。
予約面積を満たせるかどうかは、予約を1個ずつ短冊に割り当てていく評価値貪欲をします。割り当てたことで各短冊の必要な太さが決まり、短冊の太さの総和が1000以下なら予約面積を満たせます。
②短冊状に分けて、短冊内の区切り線を焼きなまし
前の処理で求めた予約の割り当てをもとに、区切り線の初期位置を決めます。
以下の遷移を使って焼きなましをします。
- 1日の区切り線1個を、その短冊上で少しずらす
- 同じ場所にある複数の日の区切り線をまとめて、その短冊上で少しずらす
- 1日の区切り線1個を、その短冊上で前後の日の区切り線と同じ場所に移動する
- 同じ場所にある複数の日の区切り線をまとめて、その短冊上で前後の日の区切り線と同じ場所に移動する
- 1日のランダムな場所に区切り線1個を持ってくる(他の短冊からも持ってくる)
- 区切りの線を選び、前後の日の同じ場所に区切り線を1個持ってくる(他の短冊からも持ってくる)
- ある短冊から別の短冊に太さを1移動させる
- 1つの短冊の太さを-1か+1する
評価値は生スコアをそのまま使用。
生スコアを計算するために、どの区画にどの予約に割り当てるかを決める必要があります。区画を面積順ソートして大きい予約から大きい区画に割り当てるのが最適なので、毎回ソートして決めます。
遷移してソートして評価、遷移してソートして評価、遷移してソートして評価・・・みたいな感じ。ソートの処理時間がボトルネックでした。
ビジュアライザ
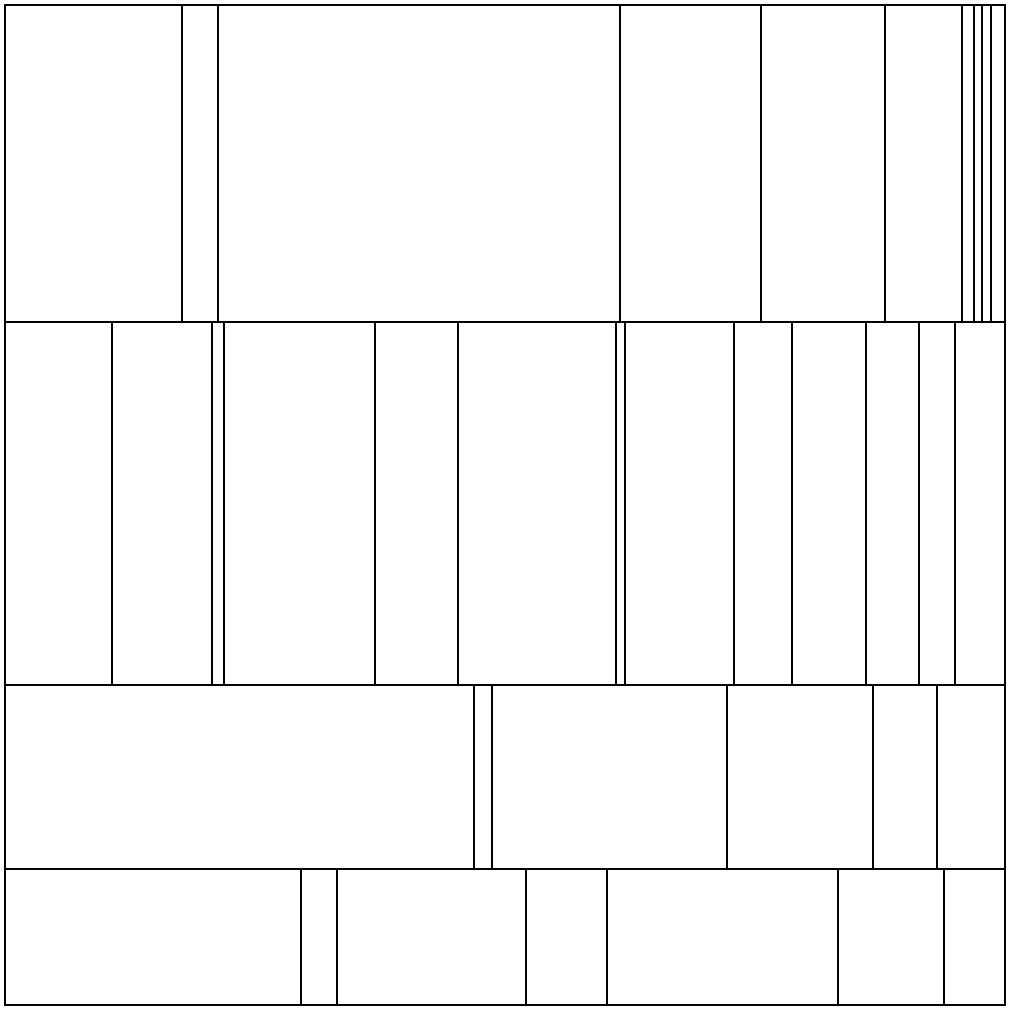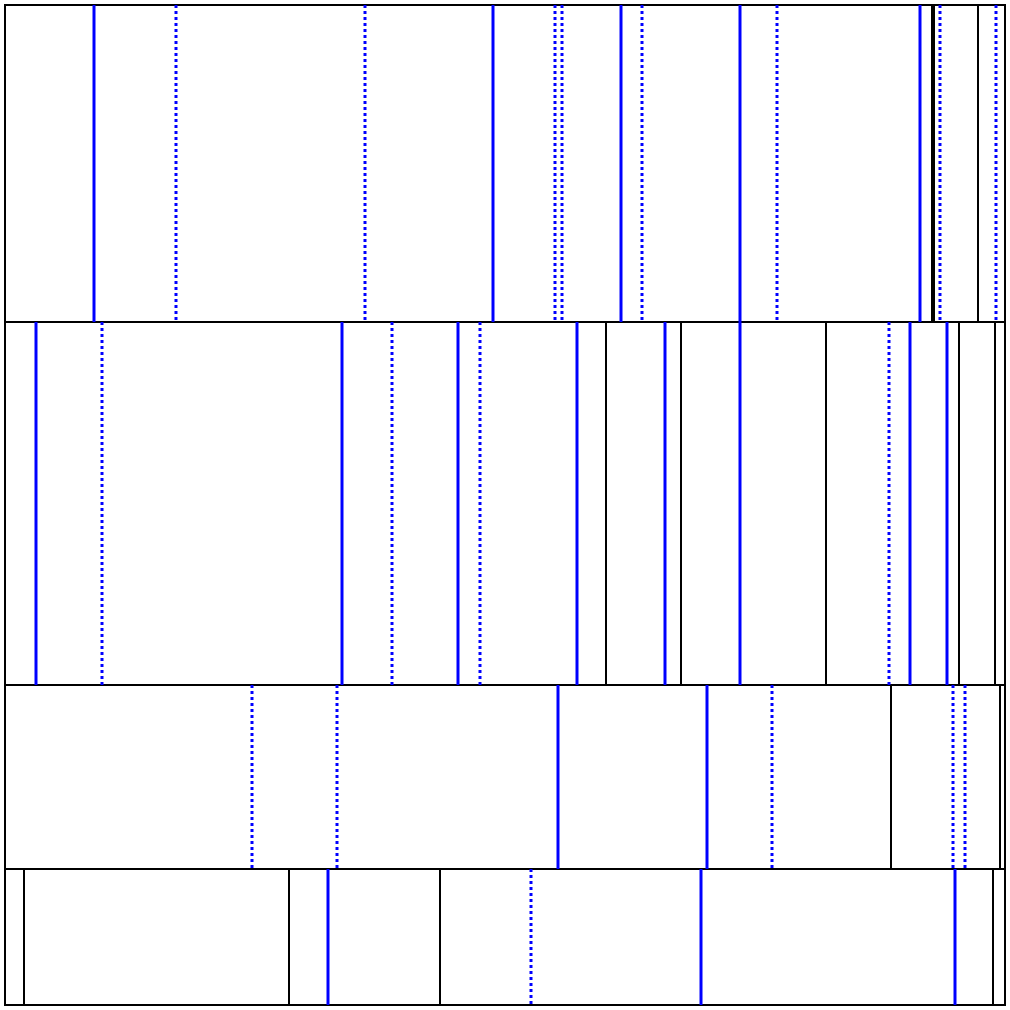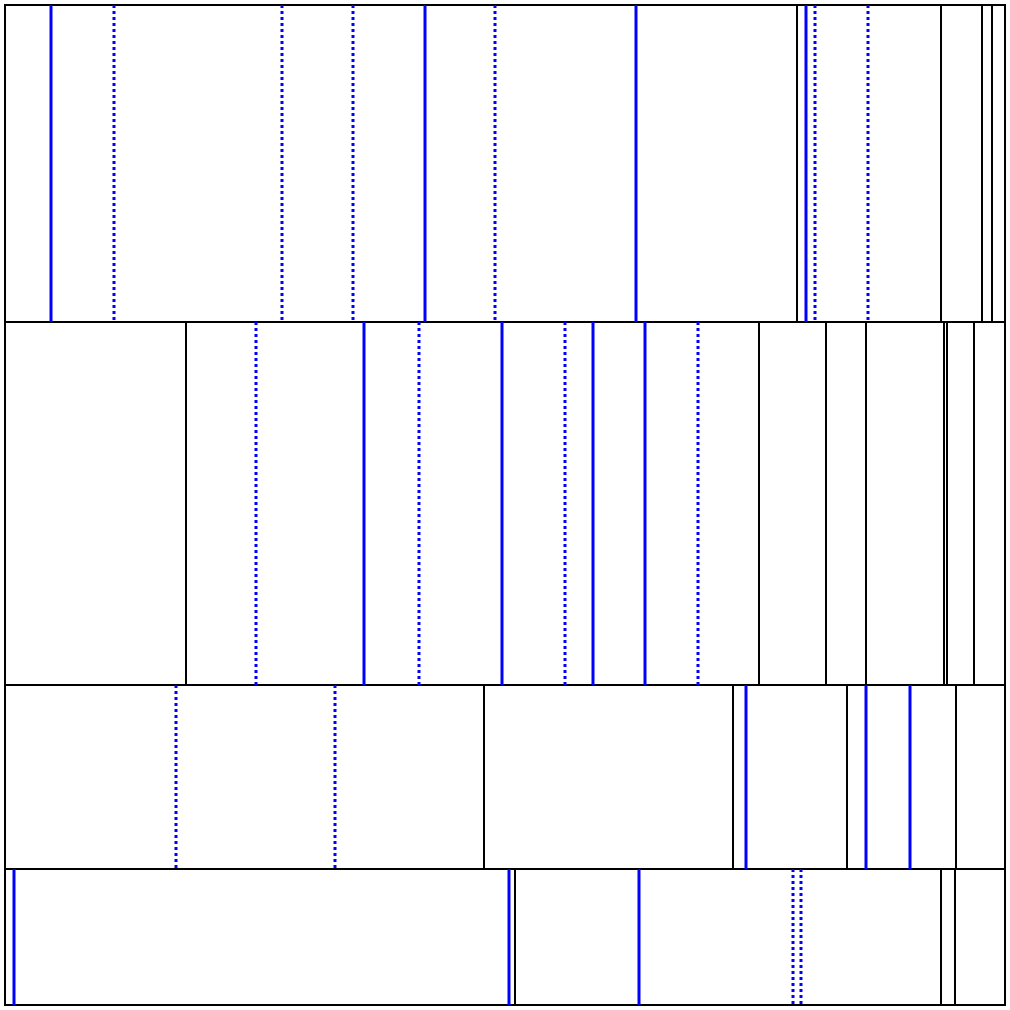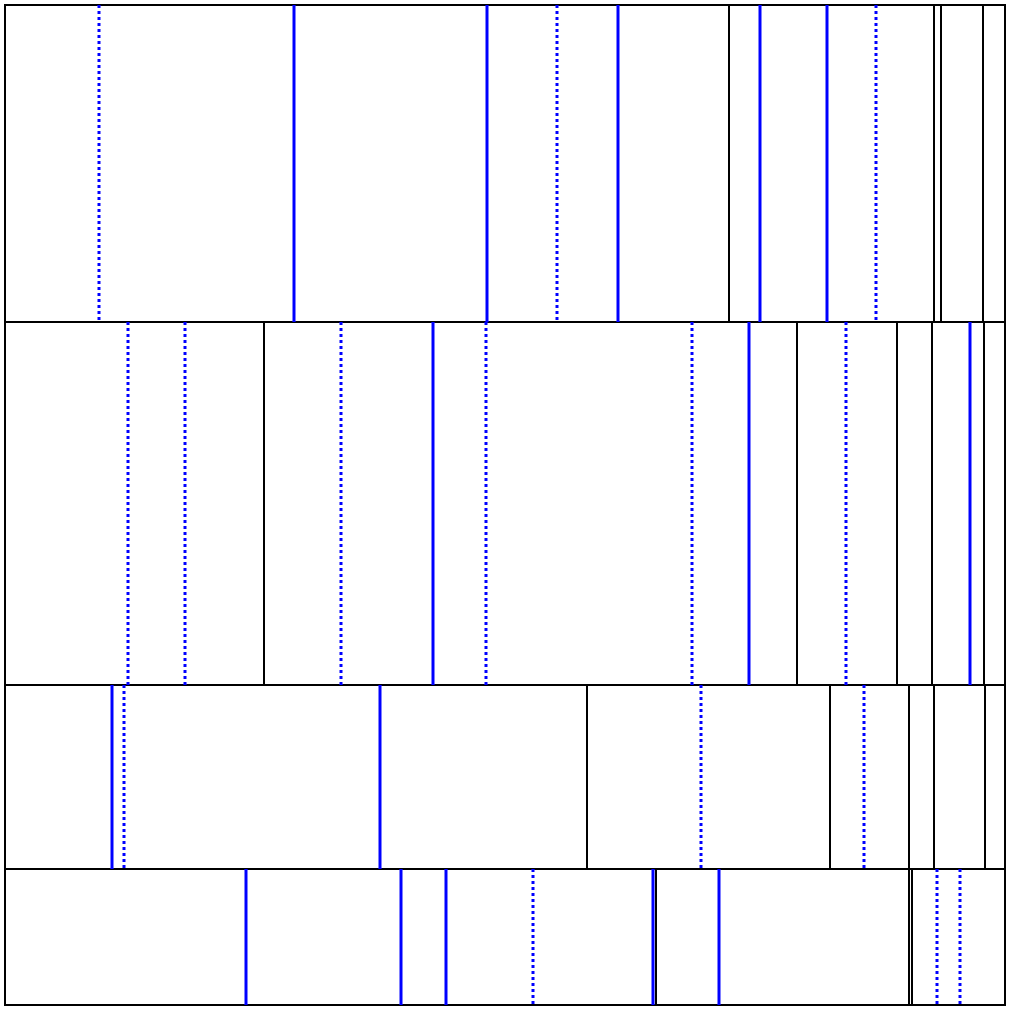
横短冊派
③空間と時間の区間を持つ木構造の焼きまなし
木構造。各ノード(頂点)は以下の情報を持つ
- 担当区画
- 担当日の範囲
- 各担当日の予約リスト
ルートノードではすべての区画、すべての日、すべての予約リストを持つ。
頂点について次の2種類の分割のどちらかを行って葉まで再帰的に展開する。
(1)担当日を何個かに分けて子ノードを作る
(2)区画と予約を2分割して子ノードを個作る
この後、ランダムにノードを選び、その子ノードを破壊~ちょっと変更して再生成の焼きなましを行う。
この解法のスコアはかなり悪くてあまり良い解法ではなさそうです。
ビジュアライザ

その他工夫:日付の圧縮
何日か分の予約をまとめて1日として扱うことで高速化しました。まとめた日はすべて同じ区切りとして出力するため、まとめた日の間の区切りコストは0になります。
その他:Wladimir Leite さんの作ってくれた統計情報
https://wladimirleite.github.io/ahc031.html

右のほうが予約面積が大きいテストケースです。
予約面積が大きい部分は解法③が使われるはずで、スコアが悪いことがわかります。
感想
コンテスト序盤~中盤は、領域を2分割していくような木構造で考えていて実装が難しかった。難しい実装をしたのに順位は全然上がらないので、何かしらシンプルで強い解法があることは予感していたが、なかなか見つけられず。
短冊解法はコンテスト終盤で思いついて、実装も簡単なうえに高速化するほどスコアが上がって面白かった。短冊数を決めるところは時間が無くて検討できなかったので、そこで差がついているのかなあ。ぐぬぬう……
RECRUIT 日本橋ハーフマラソン 2023夏(AtCoder Heuristic Contest 022)
RECRUIT 日本橋ハーフマラソン 2023夏(AtCoder Heuristic Contest 022)に参加しました。
結果は15位でした。頑張ったぞー
コンテストページ
解法
いろいろやりましたが全部書くと大変なので、特に良くできたと思ってる推定部分だけ書きます。
※数学的に正しいかどうかはかなり怪しいです
誤差について
計測時の誤差は平均0、標準偏差Sの正規分布であると問題に書かれています。
正規分布の累積分布関数を使うことで、誤差の値からそれが発生する確率を求めることができます。
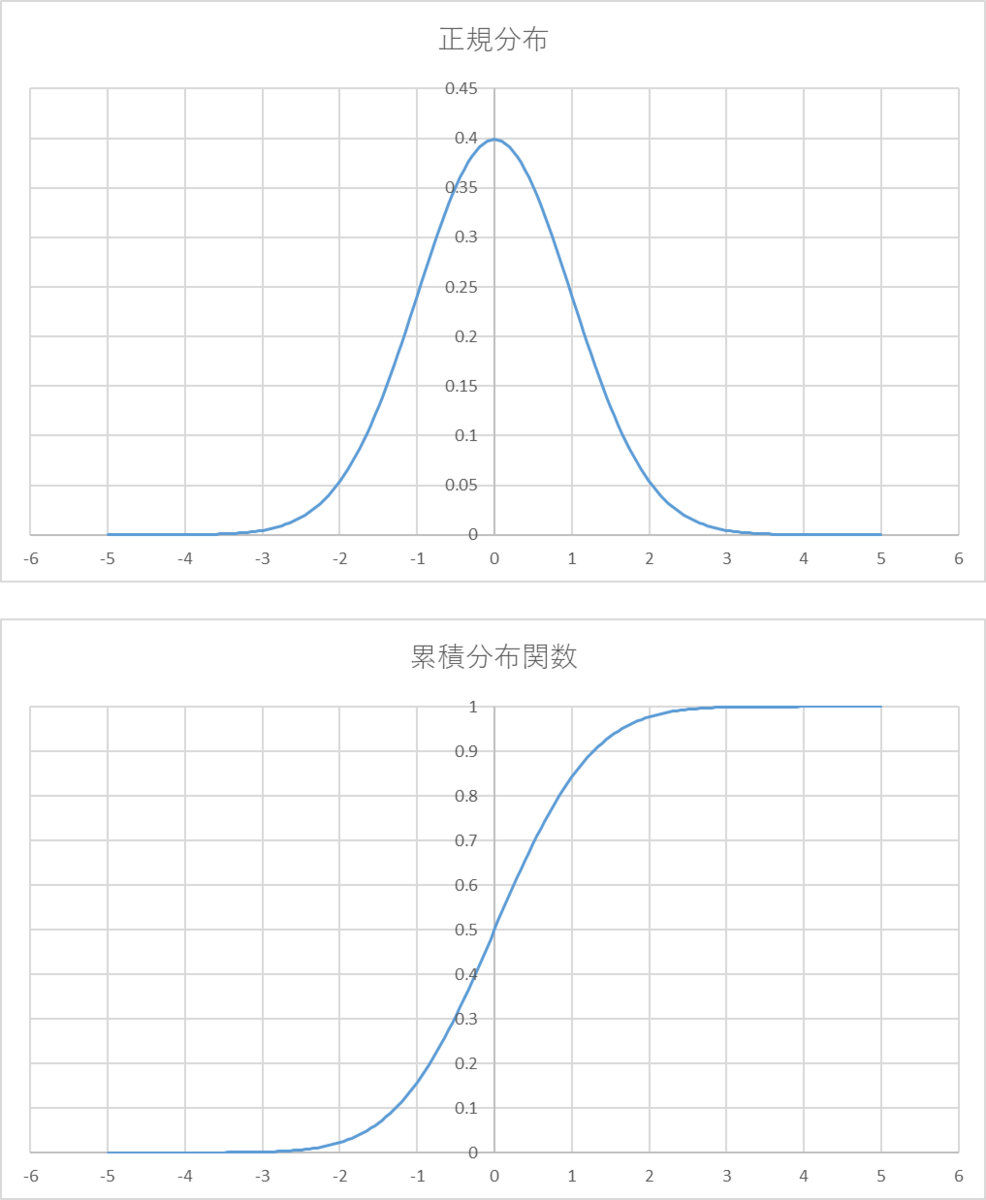
累積分布関数をf(x)とすると、f(x)はx以下の値が発生する確率を表しています。
f(b) - f(a) とすれば、値がa~bの範囲内になる確率を計算できます。(累積和みたいなもの)
式は以下のようになります。(※今回の問題に合わせて平均0標準偏差Sとして整理したものです。一般的な式はwikiなどを見てください。)
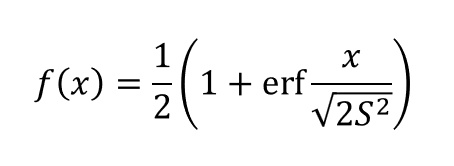
erfというのは誤差関数というものらしいです。C++にerfを計算する関数が用意されていたのでそれを使いました。
例えばS=1の時、温度が100である出口を調べて101が取得されたなら、四捨五入を考慮すると発生した誤差は+0.5~+1.5の範囲です。
この誤差が発生する確率はf(1.5) - f(0.5)=0.2417...つまり24%ぐらいのことが起こったことになります。
もう一つ例、S=900の時、温度が500である出口を調べて1000が取得されたら、発生した誤差は+499.5~+∞の範囲と言えます。累積分布関数には無限大を入れることもできて、f(∞) - f(499.5)=0.2894...つまり29%ぐらいのことが起こったと計算できます。
推定方法
各入口が各出口につながっている確率の表を作り、計測のたびに表を更新していきます。
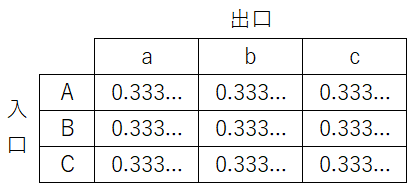
説明のために入口と出口がそれぞれ3つのケースで考えます。S=625とします。
まず表の初期状態はすべて等確率にします。
入口Aを移動(0,0)で計測した結果、温度400が取得されました。
移動(0,0)の場合、各出口につながっているとした場合の温度は次のようになっているとします。
- 出口a: 0
- 出口b: 500
- 出口c: 1000
入口Aと出口aがつながっているとすると、温度0のものが400として取得されたということなので、発生した誤差は399.5~400.5になります。この誤差が発生する確率は0.0005201..となります。
他の出口も同様に計算すると
- 出口a: 0.0005201
- 出口b: 0.000630189
- 出口c: 0.000402631
となります。
必ずどれかの出口につながっているはずなので、合計が1になるように正規化(全要素の合計値で各要素を割る)します。すると
- 出口a: 0.335...
- 出口b: 0.406...
- 出口c: 0.259...
となりました。
この値は、入口Aが各出口とつながっていた時に温度400という出来事がどれだけ起こりやすいかを表しています。(尤度と言います。確率ではないはず?)
厳密には確率値ではないのだと思いますが、合計が1になるようにしてあるのでこれ以降は確率と呼んでしまいます。よって、今回の計測結果だけを見ると入口Aは出口bにつながっている確率が40.6%だったといえます。
得られた確率値を使って表の更新を考えます。
まず計測した入口Aに関しては今得られた値をそのまま乗算します。
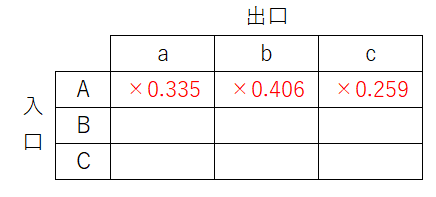
計測しなかった入口B,Cにも影響があるはずです。例えば入口Aが出口aとつながっている確率が高いと算出されたなら、入り口Bが出口aとつながっている確率は下がるはずです。
これを表現するために、出口側から見たときの合計が1になるように他の入口にも分配するような形にしました。
出口aから見ると入口のどれかに必ずつながっています。出口aが入口Aに0.335の確率でつながっているとするなら、それ以外の入口につながっている確率は1-0.335=0.665、それ以外の入口は2個あるので等分して、0.665/2=0.3325となります。
同様に他の出口でも行うと、以下のように表を更新することに決まりました。
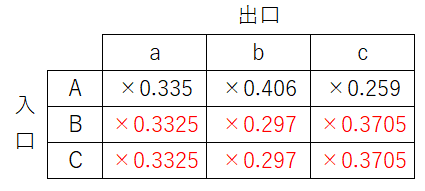
元の表にこの更新を掛けると
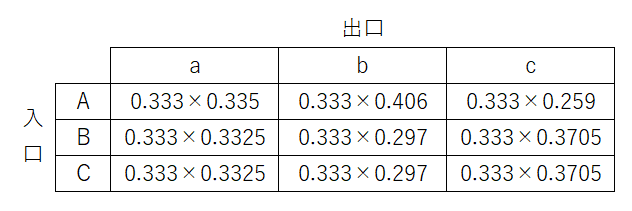
となり
上記のようになりました。
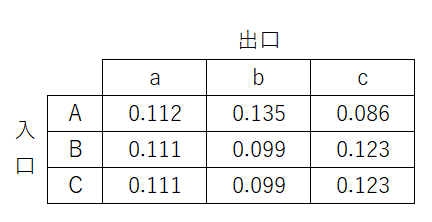
この計算を行うと横方向の合計が1にならなくなるため、行ごとに合計値が1になるように正規化をします。(正規化しないと数値がどんどん小さくなっていき、プログラム上で表現できなくなり0になってしまう、という問題もあります。)
正規化した結果が以下の表です。
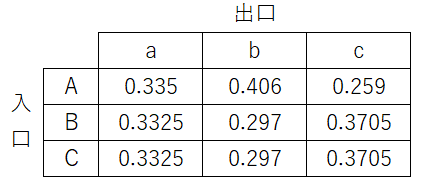
横方向の正規化により、入口がどの出口に対応するかの確率値としては見れますが、出口側から見てどの入り口に対応するかという確率値としては見れなくなります。
そのため、入口Aが出口bにつながる確率が90%で入口Bも出口bにつながる確率が90%のような、複数の入り口が同じ出口につながってしまう状態が発生します。この状態は必ず間違っているため、この状態が解消されるまでは回答を出力しないようにし、間違いを識別するための計測を優先的に行うようにしてました。
ここまでが1回の測定結果を受けての表の更新の流れです。これを計測のたびに行い、表を更新してきます。繰り返していくとだんだん正解の入口出口の組み合わせの確率が上がっていきます。
全ての入口と出口の確率が一定以上になったら計測を終了し、回答を出力します。
表が更新されていく様子の可視化
縦がワームホール、横が出口の確率行列を更新していく様子。#AHC022 #rcl_procon pic.twitter.com/RoCct6dXks
— bowwowforeach (@bowwowforeach) 2023年8月20日
コンテスト後に知ったこと
横方向を正規化するところで、縦方向にも正規化をすると良いらしいです。
これを行うと複数の入口が同じ出口につながることが自然になくなります。実際にやってみたらスコアも結構上がりました。
また、出口側から入口につながる確率もおそらく使えるようになるので、高温に近い出口を優先して調べるといったことも可能になりそうです。まだまだできることはあったんだなあ。
以上、推定って難しい!
プリム法ベースのシュタイナー木
AHC020でシュタイナー木を作るような問題がでました。そこでプリム法ベースのシュタイナー木を作ることがあったのでその方法を説明します。
シュタイナー木とは
グラフとターミナルと呼ばれる頂点集合が与えられたとき、ターミナルを全てつなぐ木のことをシュタイナー木といいます。
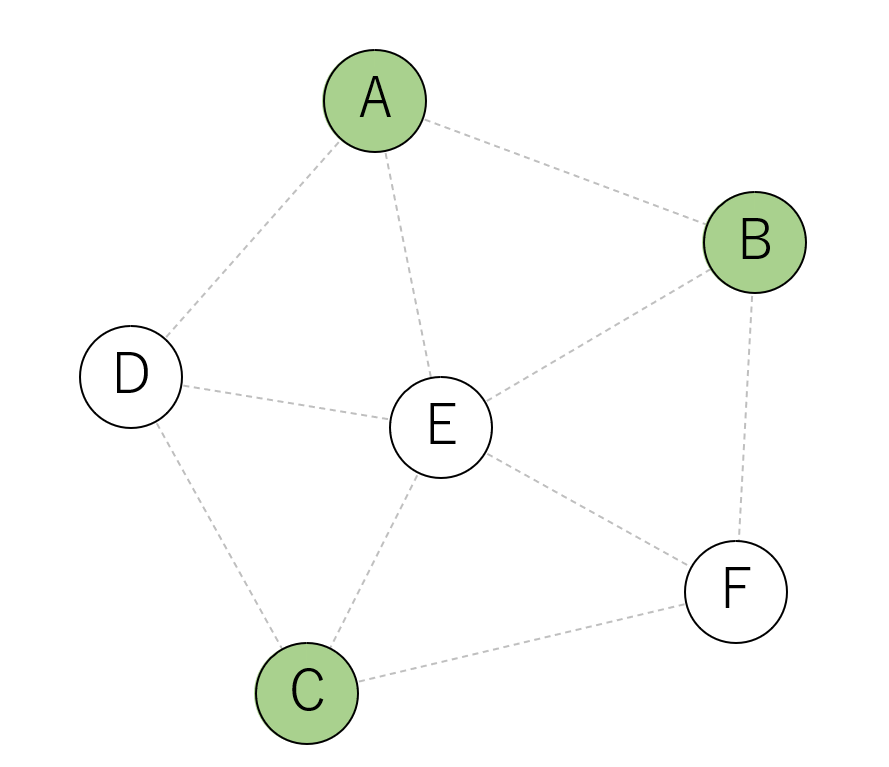
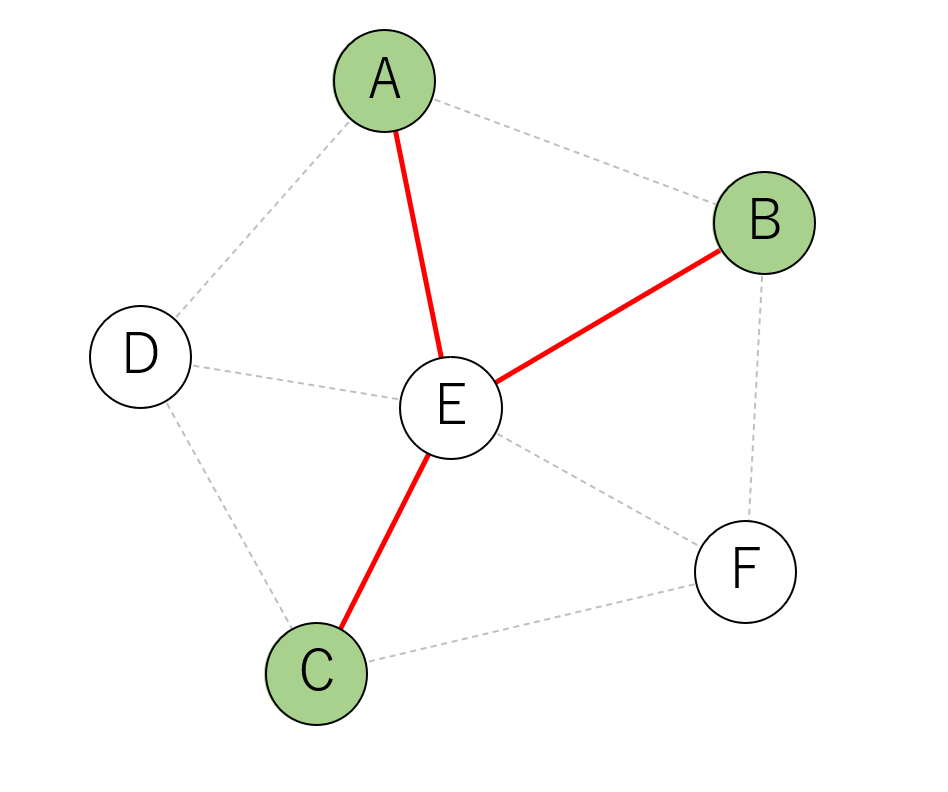
ターミナルでない頂点はつないでもつながなくても構いません。
シュタイナー木のうちコストが最小のものを最小シュタイナー木といい、これを求めるアルゴリズムとしてDreyfus-Wagner法というものがあるらしいです。しかしこの方法はとても計算量が多いです。
今回紹介するプリム法ベースのシュタイナー木は、計算量は少なくて済みますがコストが最小になるとは限りません。ヒューリスティックコンテストにおける焼きなましの最中など、厳密さより速度が優先されるようなケースでの使用を想定しています。
プリム法ベースのシュタイナー木
手順
- ターミナル頂点の1つを選び、木に含めます。
- 木から最小コストでつなげられるターミナル頂点を選び、経路をつなぎます。経路上の頂点すべてを木に含みます。(コストと経路はダイクストラ法等で求めます)
- すべてのターミナル頂点が木に含まれるまで手順2を繰り返します。
例
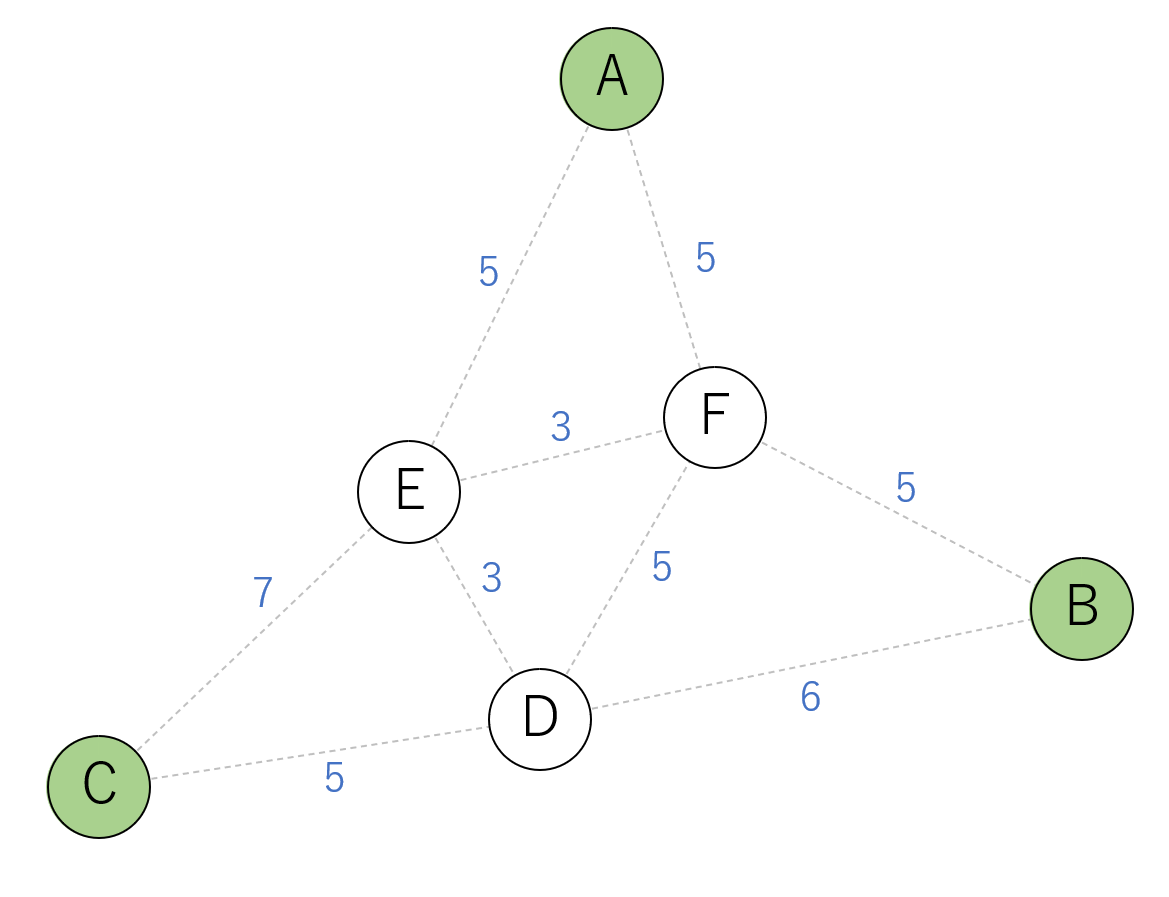
まず、ターミナル頂点Aを木に含めます。
木から残りのターミナル頂点へのコストは
- 頂点B: 経路AFBでコスト10
- 頂点C: 経路AECでコスト12
最小コストでつなげる頂点Bとつなぎます。

木には頂点A,F,Bが含まれています。
木から残りのターミナル頂点へのコストは
- 頂点C: 経路FDCでコスト10
頂点Cとつなぎシュタイナー木の完成です。
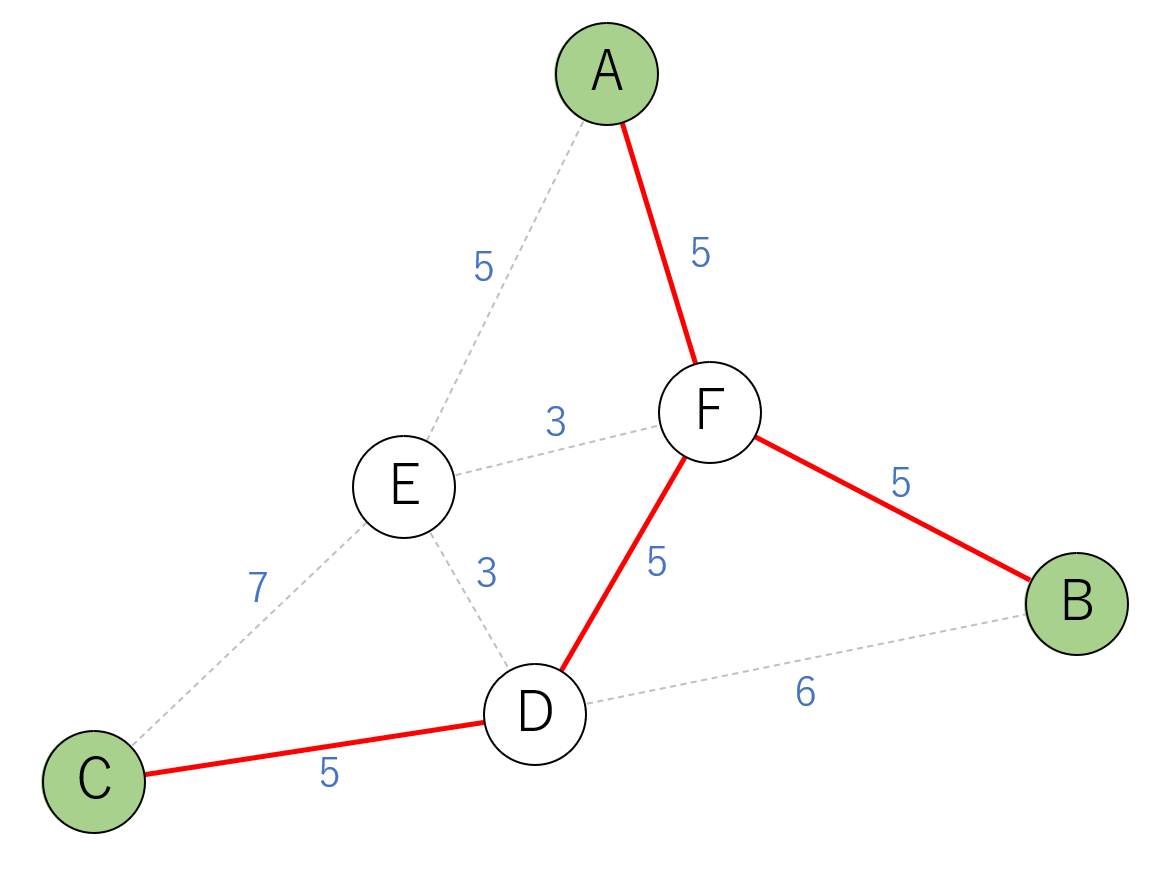
総コストは20となりました。
これは最小コストではありません。以下の図のようにつなぐとコスト19の最小シュタイナー木が作れます。
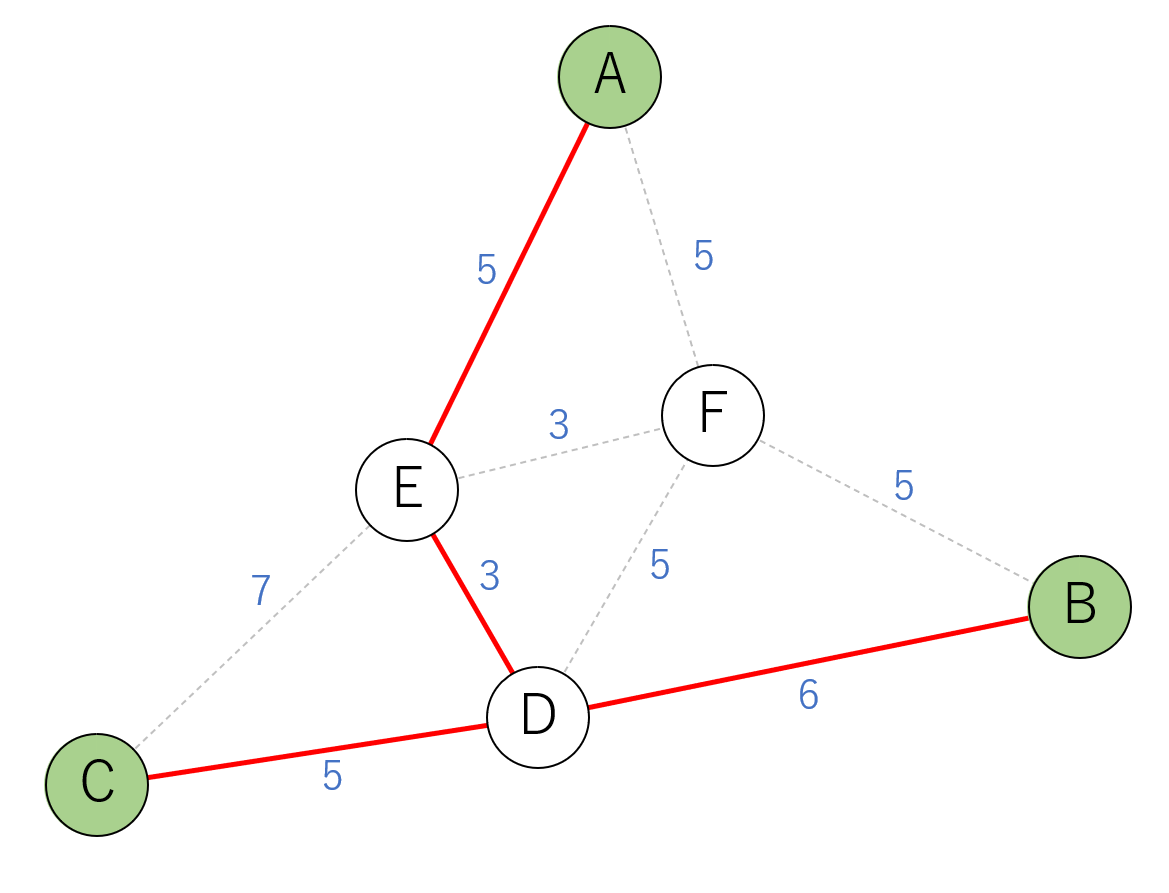
この例では最初に木に含める頂点をCにすれば最小コストになりますが、与えられたグラフとターミナルによっては、どの頂点を最初に選んでも最小コストを達成できないケースもあります。
まだ木に含まれていない頂点のうち、最小コストでつなげられるものを木に含めていく、というところがプリム法と同じ考え方です。
以上。
トヨタ自動車 実課題プログラミングコンテスト 2023 Spring
トヨタ自動車 実課題プログラミングコンテスト 2023 Spring に参加しました。
結果は優勝だー!やったぞー
以下解法です。(提出したサマリーとほぼ同一です)
コンテストページ
解法
最終提出コード
提出 #39889806 - トヨタ自動車 実課題プログラミングコンテスト 2023 Spring (atcoder.jp)
Bottom-Left 法と MCTS(Monte Carlo Tree Search)をベースとしたアルゴリズムです。
荷物の置き方を Bottom-Left 法のように(0,0,0)の点に向かって詰めて置くことにし、MCTS で置き場所/荷物の順番/荷物の回転を探索します。
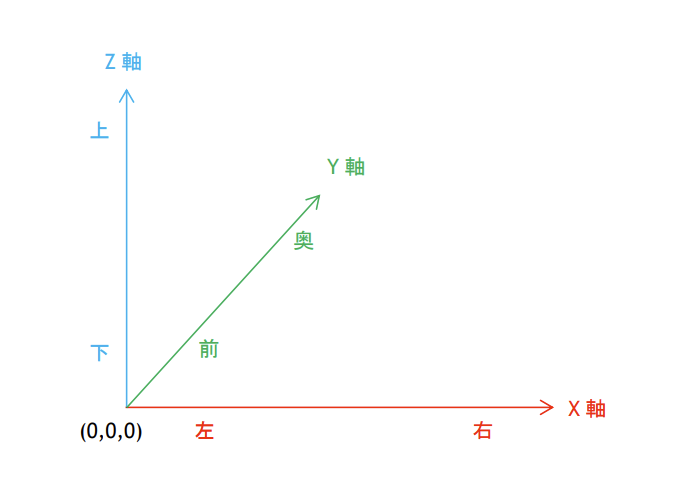
方向の呼び名
メイン処理フロー
提出コード 3455 行目~3503 行目
得点計算式より、入力されたテストケースが収容可能かどうか、順番通りに詰め込めるかどうかを判断することが重要と考えました。
まず収容可能であると決め打って一定時間探索します。決め打つことでコンテナからはみ出るような選択肢を除外した探索ができます。もし一定時間で収容可能な解が見つからないなら、収容不可能と判断します。
収容可能な解が見つかった場合、順番通りに詰め込めると決め打って一定時間探索します。こちらも決め打つことで順番通りにならない選択肢を除外した探索ができます。もし一定時間で順番通りに詰め込める解が見つからないなら、順番通りに詰め込めないと判断します。
この判断結果により 3 つに分岐、それぞれの目的に合わせた探索を制限時間まで行います。
-
収容不可能 ⇒ はみ出る荷物の体積を減らす
-
収容可能&順番通り詰め込めない ⇒ 荷物の順番前後数を減らす
-
収容可能&順番通り詰め込める ⇒ MaxHeightを減らす
判断用の探索も目的別の探索もMCTSで行っており、評価値や選択肢等の部分的な違いしかないため、これらを5つ探索モードとして定義(提出コード3399行目)、探索中にモード変数を参照して処理を分岐させています。
判断後の目的別探索をしている際に、判断を覆すような解を見つけたらそれに合わせた分岐も行います。(例:収容不可能と判断し、はみ出る荷物の体積を減らす探索を行っていたら収容可能な解を見つけたので、順番通り詰め込めるかの判定処理に遷移する。)
最後に、見つかった配置を転倒数ができるだけ少なくなるように置く順番をソートします。(提出コード3507行目~3532行目)

荷物の置き場所候補
Bottom-Left法に倣い(0,0,0)の位置に向けて詰めるようにして置きます。
基本の置き場所候補
荷物を置いた際に左面、前面、下面が他のオブジェクトに接する場所が起き場所候補となります。オブジェクトには荷物だけでなく、コンテナの壁、コンテナの底、角の直方体ブロックを含みます。
置き場所候補は荷物の大きさ(種類×回転)によって変わります。
以下の図は上から下方向を見た状態を表していて、A,Bの荷物があるとき荷物Cを新たに置こうとしています。左右の図どちらも荷物A,Bの位置関係は同じ、荷物Cの座標も同じですが大きさが違います。左の図は正しい置き場所候補ですが、右の図は荷物Cの前面が他のオブジェクトに接していないため置き場所候補ではありません。

このように、場所は一緒でも配置する荷物の大きさによって起き場所候補かどうかが変わるため、座標+サイズ下限という形で置き場所候補を表現しました。(提出コード2671行目PutPoint構造体のpoint_変数とlowerShape_変数)
探索時、荷物が置けるかどうかを判定するときにこのサイズ下限を使って判定します。
追加の置き場所候補1[真上に置く]
基本の置き場所候補だけでは困るケースがあります。

上記の図は前から奥方向を見た図です。荷物Aは上に物を置いてはならない荷物とします。
基本の置き場所候補だと、点Pと点Qが置き場所候補となります。点Qは荷物Aの幅を超えるというサイズ下限がついています。
点Pは荷物Aの上に物を置いてはいけないという条件から置くことができないので除外します。

上記左の図で、荷物Cを点Qに置けるかを考えると、サイズ下限を満たさないため置くことができません。上記右の図では、荷物Dを点Qに置けるかを考えると、サイズ下限は満たしますが、接地面積6割の条件を満たせないため置くことができません。
これらのようなケースがあるため、配置済みの荷物の真上も置き場所候補としました。
以下の図のように、荷物Bの上の点Rであれば、荷物CもDも置くことができます。

追加の置き場所候補2[接地面積ぎりぎり6割]
前述した真上に置くケースで、接地面積6割ぎりぎりの位置に置いたほうが残った空間を広くできます。

上記図のように、荷物C、DについてX軸方向にずらした時に接地面積ぎりぎり6割を満たせる位置S、Tも候補とします。同様にY軸方向にずらした時に接地面積ぎりぎり6割を満たせる位置も候補とします。(斜め方向も試しましたがスコアが悪化したため採用しませんでした。)
この置き場所候補は、荷物の種類×回転6種×2方向(X軸方向とY軸方向)分あり、数が多いです。数が多いことによる処理速度低下の問題があったため、荷物と方向につき回転は一番原点に近い場所になる1種に限定しました。
計算箇所
状態を表すデータ
提出コード2734行目のState構造体が荷物の配置状態を表し、置き場所候補も保持しています。
追加の置き場所候補
提出コード2998行目のAddItem関数で荷物の追加と置き場所候補の更新処理を行います。
提出コード3024行目~3128行目で基本の置き場所候補を計算しています。
新規に追加する荷物1個と既存のオブジェクト2個を総当たりし、新規追加される置き場所候補を計算します。ここが本アルゴリズムにおける処理時間のボトルネックであるため、高速化が重要です。
提出コード3168行目が真上に置く候補の追加。
提出コード3171行目~3258行目で接地面積ぎりぎりの置き場所候補を計算しています。
置き場所候補のマージ
提出コード2808行目のPushPutPoint関数で、既存の置き場所候補と新規置き場所候補のマージ、置き場所候補のソート、無効になった置き場所の削除、をまとめて行います。
置き場所候補のソートは探索時に置き場所の座標をXZYの優先度でソートしたものとYZXの優先度でソートしたものが必要なのでここで準備します。
既存の置き場所候補はソート済みであるため、新規置き場所候補をC++標準関数でソート、あとはソート済みリスト同士のマージとなるためマージソートのように処理します。
マージ中に、座標は同じでもサイズ下限が違うケースが出てきます。これを別な要素とするとデータ数が増えて速度低下につながるため、サイズ下限を両方の最小値にして1つにマージするようにしました。(提出コード2905行目~2916行目)
これにより置き場所としては不正(左面、前面、下面が他のオブジェクトに接しない)な候補となりえますが、探索時の走査順的にこれが採用されることはほぼないのとスコア的にも問題なかったのでこのようにしました。
探索
提出コード3537行目~3748行目
MCTSアルゴリズムによる探索を行います。
展開処理の候補手
提出コード3750行目TryNewNext関数
体積大きい順、回転後の高さが低い順(=底面積大きい順)に、置き場所候補XZY順で最初に見つけた配置可能場所と、置き場所候補YZX順で最初に見つけた配置可能場所を候補手とします。
荷物の種類×回転ごとに2つが候補手となりますが、以下の探索モードでは4つの候補手になります。
- はみ出る荷物の体積を減らすモード
はみ出る候補手とはみ出ない候補手両方を追加します。 - 荷物の順番前後数を減らすモード
順番前後する候補手と順番前後しない候補手両方を追加します。
各ノードの子ノード数には上限を設けます。そのため優先度の低い候補手は探索されません。
プレイアウト時の候補手
提出コード3933行目Playout関数
まだ置いていない荷物の中で一番体積が大きい荷物を置くことにします。XZY順とYZX順どちらにするかをランダムで決めます。置き場所候補を順に走査、各置き場所候補について回転をランダムな順番で試し、最初に見つかった場所と回転で配置します。これをすべての荷物を置くまで繰り返します。
残っている荷物のうち一番体積が大きい荷物を置けなかった時点で解が見つからなかった扱いにするのが良いようで、次の体積の荷物を置くのも試しましたがスコアは悪くなりました。
置き場所候補の2つの順序
置き場所候補をXZY順とYZX順の2つの順序で走査し両方を候補手としている理由ですが、XZY順のみだと最初に置く荷物は必ず(0,B,0)になります。すると最初に置いた荷物が邪魔でそれ以降の荷物を(B,0,0)に置くことができません。テストケースによっては(0,B,0)よりも(B,0,0)に置いたほうが良いケースがあったためYZX順を追加しました。
最初の置き場所の問題のために追加した順序ですが、それ以外の場所でも良い選択肢になっているようで、最初に限らず常にこの順序も使うようにしました。

スコア更新の見込みのないノードの枝刈り
荷物を1個配置するたびにペナルティが増えていくようなスコア設定になっているため、見つかっているベスト解よりもペナルティが増えた時点でそれ以降の探索は無駄とわかります。
提出コード3281行目CanPutBest関数にて、配置可能かの判定とベストスコア更新の見込みがあるかどうかも判定しています。提出コード4127行目~4146行目のIsNoChance関数でも更新見込み判定を行っています。
判定の際に簡易的な転倒数(変数名easyInversion)を使って判定している箇所があります。簡易的な転倒数は荷物の上下の位置関係により転倒数を増やしてしまうペアの個数です。実際の転倒数はこれ以上になります。転倒数計算が重かったため用意したものですが、最終的に転倒数計算が高速化されたため不要だったかもしれません。
その他工夫点
ノードに状態を持たせない
ノードに状態を持たせず、ノードをたどりながら状態を計算していくことでメモリ使用量を減らしています。おそらくその分パフォーマンスは落ちていますが、メモリ制限に引っかかる可能性があったためこのようにしました。
ノード選択指標
ノードを選択する際の指標は[UCB1-Tuned]を使用します。これはよくMCTSの説明で使われる[UCB1]よりも性能が良いとされています。実際にUCB1よりもスコアが良かったので採用しました。(提出コード2656行目~)
ベスト解まで展開
探索を始めるときとベスト解を見つけたとき、ベスト解のノードまでノードを展開します。
これによりベスト解に近い選択肢が選ばれやすくなることを期待して入れましたが、それほどスコアに寄与していないようです。(提出コード3547行目~3579行目、3610行目~3655行目)
メモリプール
ノードの展開に際して動的にノードを追加していくことになりますが、動的メモリ確保は時間がかかります。あらかじめ大容量のメモリを確保しておき、その領域から必要な分を少しずつ取ってきて使うことで、動的メモリ確保の回数を減らし高速化しました。
置く順番ソート
できるだけ転倒数が少なくなるようにソートします。
2つの方法を用意しました。どちらも最適解を出す解法ではありません。両方試して転倒数が少ない方の結果を使用します。(スコア計算式的に転倒数の重要度は高くないと考えたため、あまり検討していません。)
方法その1
提出コード2226行目SortedNew関数
荷物を順番通りに置いていきますが、上下関係により依存する(=先に置かなければならない)荷物があるならそれらを置いてから置きます。
もし同じ種類の荷物で、他の荷物に依存する荷物が複数あるなら依存数が少ないほうから選んでいきます。例えば同一種類の荷物AとBがあり、Aは3つの荷物に依存、Bは2個の荷物に依存しているとします。この場合は荷物Bのほうが依存する荷物が少ないためBの荷物を先に置きます。
依存する荷物を先に置く際も、荷物を順番通りに置いていき、依存するものを先に置くということを行うので再帰的な処理になります。
方法その2
提出コード2189行目SortedOld関数
トポロジカルソートの要領で行います。置ける状態になっている荷物のうち一番種類番号が小さいものを置くということを繰り返します。
bit演算による高速化
大抵のケースでは荷物の個数が64個以下であるため、64bit変数を使ったbit演算で高速化を行っています。一応64個を超えるケースも存在するため、方法その1のbit演算を使用しない版も用意してあります。(提出コード2464行目SortedIndexOver64関数)
解法は以上です。
感想等
コンテスト序盤は先行研究があると思っていろいろ調べていた。
シーケンスペアとかシーケンストリプルとかいうのを見つけて、これなら焼きなましできるやったぜと思って実装してみたら、スコアが伸びず単純なBottom-Left法にも負けていた。今回の問題設定だとおそらくうまくいかないことがわかってきて方針を変えた。(角の長方形オブジェクトと接地面積6割あたりが原因)
Bottom-Left法は単純すぎてあんまり使えるとは思ってなかったけど、いろいろ試した中では一番スコアが良くて、これをベースにちょっとランダムに散らすのを考えた。さらに、良い解が出た場合は途中の状態も良い状態になっていて、途中からまたランダムに散らすようにすればいいのではと思い、これってMCTSでは?ってなって実装してみたら良いスコアが出て方針が固まった。
高さを制限してその制限に収まるかどうかを判定、みたいな2分探索的な解法を思いついて、それが5つのモード遷移という形になった。制限時間が決まっているのでその中で時間を区切って判断したけど、実務で使う場合はそれぞれ決め打ちして3回実行すれば良さそう。(これサマリーに書けば良かったな)
スコアがぶれやすい(条件を満たすかどうかでスコアが大きく変動する)ので、修正が良いものかどうかの判断が難しかった。ローカルでは1000件でテストしていたけどそれでも足りなかった気がする。毎回ベスト解が出ているような簡単なケースは除外して難しいケースを増やすと良かったかもしれない。
サマリー賞があるということで、頑張って書いてみたけどなかなかうまい表現ができなくて悩んだ。期限もあるし疲れたしで力尽きた。AIにお願いしたらうまいことやってくれるのかな。
コンテスト2週間+サマリー1週間でトータル3週間の長い戦いでした。やっと休めるよ……
THIRD プログラミングコンテスト 2022 (AtCoder Heuristic Contest 017)参加記
THIRD プログラミングコンテスト 2022 (AtCoder Heuristic Contest 017)に参加、優勝しました!
コンテストページ
問題概要
沢山の頂点と辺(道)があってすべての辺を1回ずつ工事したい。
工事中の辺は通れなくなり、それにより頂点間の経路が伸びるとその分だけ不満が溜まる。
不満ができるだけ少ない工事日程を決めてください。
提出コード
最終提出コードをちょっとリファクタしてコメントを付けてみました。
https://atcoder.jp/contests/ahc017/submissions/38692385
以降の解説で説明が難しい箇所にコード行番号を記載します。
解法
山登り法をしました。
基本的な処理の流れは次のようになります。
(1)初期解の計算
辺1つずつ貪欲に工事日を決めていきます。
ある辺について、それぞれの日に工事した場合の評価値を計算し、一番評価の高い日に工事します。評価値は問題自体のスコア(ただし頂点間引きしている)と、工事が特定の日に集中しないようにその日の工事数で減点します。
処理する辺の順番が重要で、あらかじめ2点間の最短経路をたくさん出しておき、その中で長い経路のほうから辺をたどっていくような辺の順序にします。こうすることで、連続した道が同じ日に工事されやすくなります。(提出コード2331行目~)
(2)山登り
ランダムな辺の工事をキャンセルし、別な工事日にしてみてスコアが上がるなら採用、上がらないなら元に戻す、ということを時間いっぱい繰り返します。
ここでは2種類の遷移を行っています。
- 遷移1:1辺を選んで工事日を変える
- 遷移2:1頂点を選んでその周りの辺全部の工事日を変える
遷移1だけだと工事日がだんだん変わらなくなっていくので、遷移2のような大きい変化が必要でした。
以上が基本の流れで割と普通の山登りだと思います。
この問題で重要なことはスコア計算が重いことです。愚直にスコア計算すると初期解の計算ですら制限時間内に終わりません。これをいかに高速化したかを説明していきます。
代表点を使う(頂点を間引く)
問題のスコアはすべての頂点間の距離を計算する必要がありますが、頂点をいくつか間引いても実際のスコアと近い変動をするので間引いてしまいます。
間引き方は以下の2種類使用しました。
- 頂点番号で間引く(5N+1番頂点だけつかうみたいな)
- 頂点間の距離が一定以上になるように間引く(以下の図のピンクの点みたいな感じ)

間引いた状態で山登りをしていると、正確なスコア計算ではないためか実際のスコアが上がらなくなる現象が発生します。時間とともに代表点を増やしていくことで速度とスコア精度のバランスをとりました。最終的には32段階に代表点を増やしています。
山登りの遷移処理においては、まず少ない代表点ですべての日の工事を試してみて、一番良かった日について代表点を増やして再度スコア計算、これがもとのスコアより上がっていたら採用、というような2段階の評価をしています。
スコア計算の差分更新
スコア計算のためには、各日の全頂点間の距離を計算する必要があります。
ある1辺の工事をする時に変化があるのは工事する日の全頂点間距離のみなので、各日の全頂点間距離情報を保持しておくことで、変更のあった日のみ再計算で済みます。
さらに、工事をすることで影響がある箇所は限定的なのでその部分だけ再計算すれば済みます。
以下の図は、ピンクの点を始点としてそれ以外の頂点までの最短経路を青線で示したものです。最短経路はダイクストラで計算していて、各頂点は始点からの距離と1つ前の頂点からどの辺を通ってきたかという情報を持ちます。

以下の図は赤線の辺を工事したときに、再計算が必要になる頂点を緑色にしています。
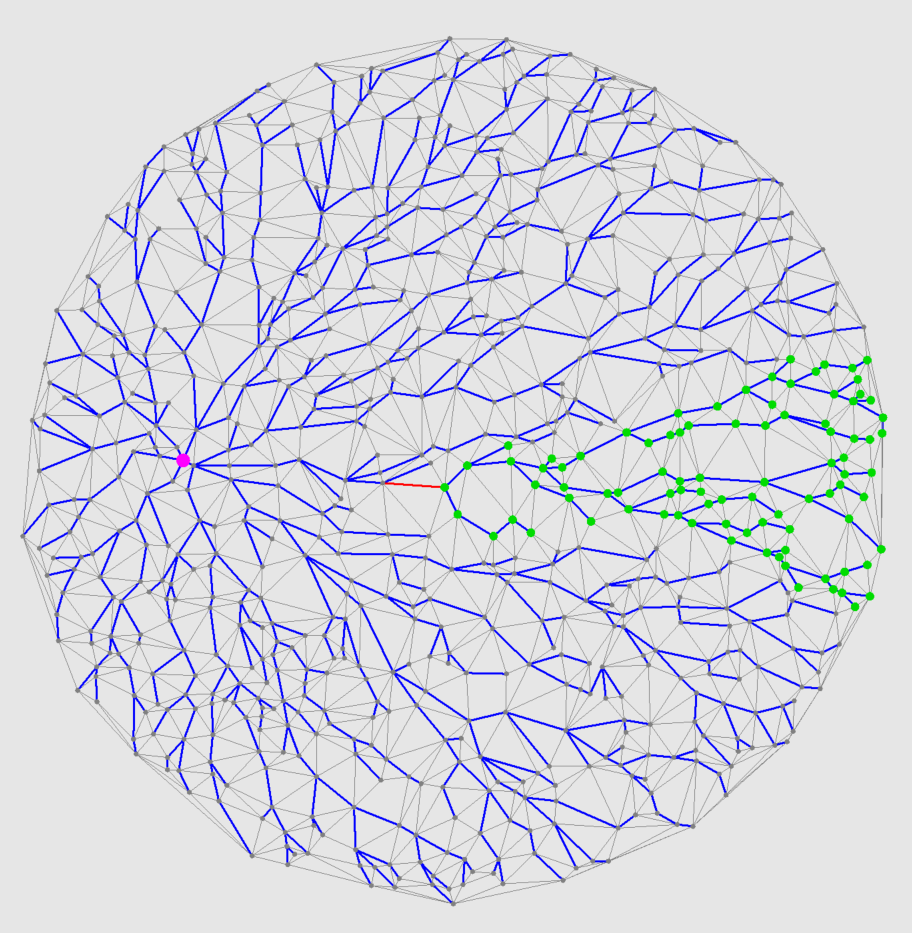
この図を見てわかる通り、最短経路は木構造のようになっているので、工事した辺以降の部分木の範囲だけ更新すればよいです。
以下の図は、赤線の辺を工事したときの最短経路の変化のGIFです。

実装は、部分木を辿って更新が必要な頂点の距離をINFにしておき、その周りの更新不要な点を優先度付きキューに入れてダイクストラを行えば差分更新できます。
さらに、更新しても頂点間の親子関係が変わることが少ないため、BFSでたどった順番に更新処理を行っていくだけで大体は更新完了します。それで更新しきれない部分だけダイクストラすることで高速になりました。(提出コード1465行目~)(高速化の話は1930行目~1966行目あたり)
工事をキャンセルする場合は、辺の両端にある頂点の距離がその辺を通ることで縮むのであれば更新が必要で、遠いほうの頂点の距離を更新し優先度付きキューに入れてダイクストラを行えば差分更新できます。(提出コードの1507行目~)
スコア計算の打ち切り
初期値計算や山登り遷移の際に、それぞれの日に工事してみて一番良い日を選ぶという貪欲を行います。その際のスコア計算中に、それまでに調べた他の日のベストスコアより悪くなった時点でもうその日に工事する見込みはなくなるため、スコア計算処理を打ち切りるようにしました。
解法については以上です。
コメント
頂点を間引いたところからまともに山登りができるようになって楽しくなった。これを思いつけなかったら何もできずに終わってたかも。高速化でスコア上がるのは楽しい!
連続した道を同じ日に工事するのが良さそうというのは、じっくり山登りさせたことでわかってたけど、最後まで評価値に落とし込むことができなかった。たまたま試した辺の順序変更がうまくいってるみたい。でもあんまり良い方法ではないような?
頂点の間引き方は、等間隔以外にも外周に近いところだけにするとか試してたけど、最終日のごたごたでコードを巻き戻したりして採用できなかった。
最初スコア計算するときに全頂点間距離ならワーシャルフロイドやろーでやったら遅すぎてダメだった。これ過去に別なコンテストで同じことしてる……
おまけ:コンテスト中の動き
スコア計算実装→遅すぎぃ
貪欲してみる→TLE
じっくり時間をかけて山登り→連続した辺を工事するのがいいみたい
ダイクストラ差分計算→貪欲でぎりぎりTLEにならないぐらい
貪欲を頑張るしかないと思っていろいろ評価値考えてみる→日ごとの工事数の偏りを減らすのは良くなった。そのほかにいい評価値は出ず。
頂点を間引いてみた→計算が早くなって山登りができるように。
初期解貪欲の辺の順番をいじってみた→いい感じ
いろいろ高速化。
山登りの評価値いろいろ試したけど良くならず。
間引き量を増やすほどローカルではスコアが上がったが、最終日、提出したらスコアが下がる。なんでえ?
原因調査のためコードをロールバックしたりしてごたごた。
原因はローカルでの処理時間不足(3秒でやってた)により山登りが収束していないため。ジャッジサーバー上では6秒だから収束している→時間が余ってるなら間引き量を減らして精度を上げれるじゃない。
間引き量を徐々に下げたほうがスコア上昇が早そう→良くなった。
ロールバックしてしまった改善点を入れてくが全部は間に合わない。精神的にもつらくて手が動かない。
ちょっとパラメータ調整して終了。
おつかれさまでしたー
CodinGame Fall Challenge 2022 解法とか
CodinGame Fall Challenge 2022に参加しました!
2位でした!ムキィー!

ゲーム内容
tsukammoさんによる要約です。いつもありがとうございます。
tsukammo.hatenablog.com
最終的なbot
目標セルとユニットの割り当て
未占領の各セルについて、相手と自分が最短何ターンで到達できるかを計算し、相手のほうが先に到着できるセルの周りのセルを目標セルとします。(自分と相手の同距離のセルは目標セルになる)
目標セルのうち、壁際にあるセルを重要目標セルとし、優先的に狙うようにします。
目標セルは連続でとれるような配置になっている場合は一番近くの目標セルのみを抽出。
ユニットと抽出した目標セルを到達ターンをコストとした最小費用流でマッチングさせます。
この時、目標セルまでのターン数が最短+1までのユニットのみ割り当てます。最短+2かかるとSPAWNしたユニットに向かわせたほうが早いからです。
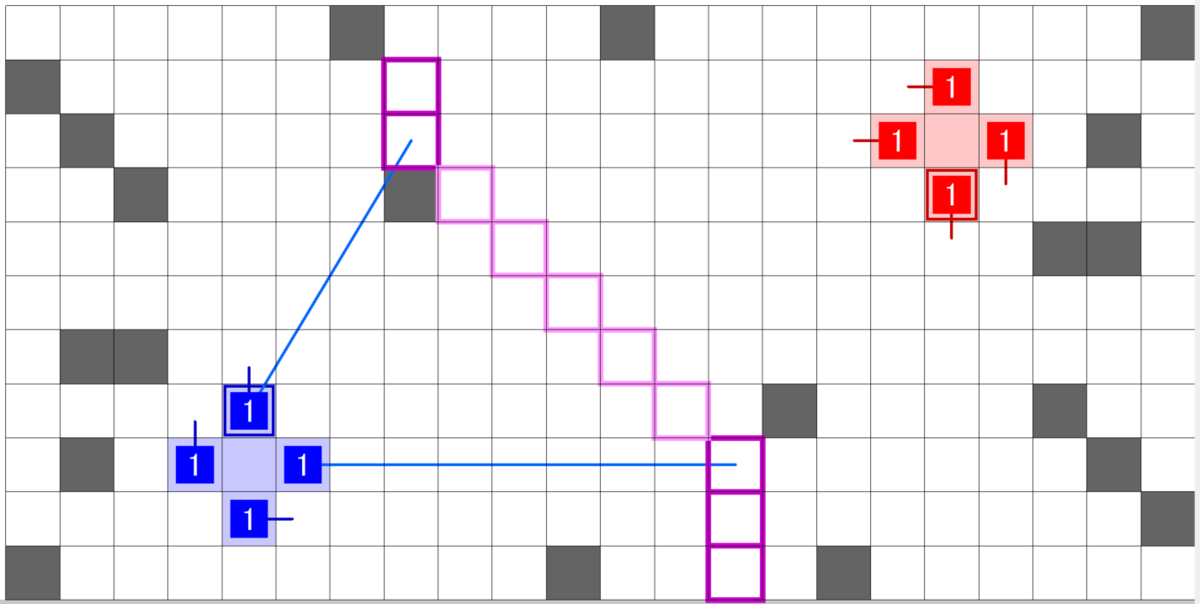
1ターン目~相手と接触するまで
1ターン目にビームサーチで相手と接触する直前までのターンを探索します。
2ターン目以降はその結果を出力していくだけです。
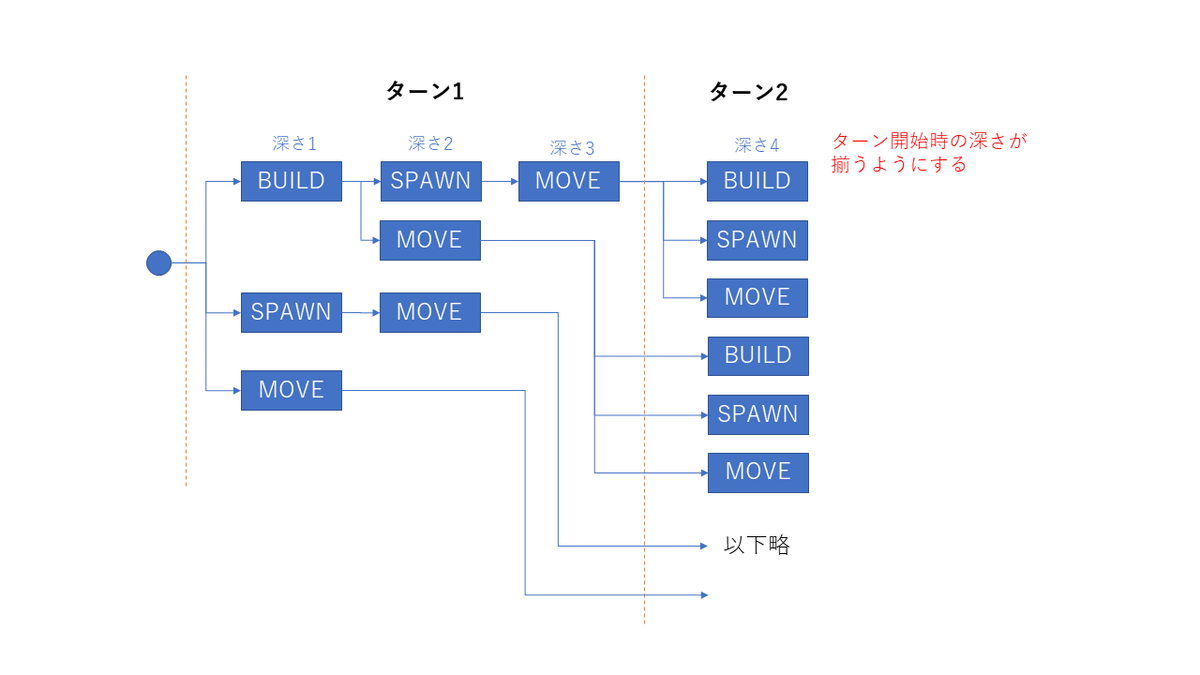
行動はBUILD->SPAWN->MOVEの順にしました。BUILD/SPAWN数やユニット数によって1ターンにおける行動回数が変わりますが、ターン開始時点の深さが揃うようにしました。
評価値
- matterが多いほど良い
- recyclerによって将来取得できるmatterが多いほど良い
- 占領したセル数が多いほど良い
- ユニット数が多いほど良い
- 目標セルとの距離が近いほど良い
- 相手側に近いほど良い
相手と接触後
以下の手順で行動を決めていきます。
- 重要目標セルへ移動
- 防衛行動
- 残りの行動
行動を決める際に評価値を使って行動後の状態の優劣を評価します。
重要目標セルへ移動
重要目標セルへマッチングされているユニットを目標セルに向けて移動させます。移動先候補が複数ある場合は評価値の高いほうを採用します。
防衛行動
こちらの占領済みセルであって、相手ユニットの周りにあるセルを防衛対象セルとします。
相手の1ユニットがこちらの複数の領域へ進める状態の場合、評価値が悪くなる方向へのみ進むものとして防衛セルを決めます。(例外的に移動されるとまずい場所は評価値にかかわらず強制的に防衛セルにします)

防衛セルのうちBUILD可能なセルを洗い出します。それらのセルへのBUILDする/しないの組み合わせはbit全探索で、BUILDされていないセルについてユニットとSPAWNをどの防衛セルに割り当てるかを最小費用流で決めます。
相手から遠いユニットを優先的に割り当てたりなど、コストを微妙に調整します。
防衛成功した割り当てのうち評価値が最大のものを採用します。
全ての防衛セルを守ることが不可能だった場合
どのセルをあきらめるかを決めることにしました。各セルのあきらめる/あきらめないのパターンをbit全探索します。
あきらめたセルへは相手のユニットが移動してきたものとして評価値を算出します。評価値が最大となるようなあきらめ方を採用します。
処理時間的に間に合わないことがあるため、処理時間を見て打ち切り、防衛セル数が多い場合は諦めるセルを貪欲的に決めたりします。
残りの行動
残っているmatterの使いみちと残ったユニットの移動を決めます。
以下の行動候補をすべて試し、行動後の状態を評価。評価値が一番良いものを貪欲的に選んでいきます。
SPAWN
- 目標セルから最短の位置にSPAWN
- 相手領域の周りにSPAWN
こちらが有利になりすぎないように、同時に相手もSPAWNしたことにする。
MOVE
- 相手領域に近づく方向にMOVE
- 相手領域+1の距離の位置にMOVE
- 上記で移動不可な場合はそれ以外の方向へも移動許可
- SPAWNしてMOVE:防衛行動が決定しているユニットの移動先位置にSPAWNし、代わりに防衛行動だったユニットを別な方向にMOVE
MOVEの際に、相手ユニットがいる場所への移動は移動する人数を制限する
相手の最大ユニット数を超えられるなら全員送る。
相手の現在のユニット数よりこちらのユニット数が多いなら、相手はこちらのユニット数に合わせてくると想定してその-1を送る(相手のユニットを0にするとBUILDされるので回避したい)
こちらが有利になりすぎないように、同時に相手もMOVEやSPAWNさせる。
BUILD
BUILDした結果壊れるセル数と得られるmatter数によりBUILDしたほうが良い度合いを計算。自分の領域が破壊されるのは減点だが、相手の領域が破壊されるなら加点する。
BUILDしたほうが良いほうから8カ所を行動候補とする。
評価値
- matterは多いほど良い
- 占領地多いほど良い
- ユニット数多いほど良い
- 将来取得予定のmatterが多いほど良い:早く取得できるほど良いようにターンで重みづけ
- 相手より先に到達できるセル数が多いほど良い
- 相手陣地に到達可能なユニット数が多いほど良い
- 各ユニットの相手陣地までの距離が近いほど良い
- 各ユニットの2マス以内に相手占領セルが多いほど良い、相手側の未占領セルが多いほど良い。相手側の未占領セルとは相手の占領地を通らないと到達できない未占領セルのこと。
- ユニットのいるセル数が多いほど良い(ユニットが同じセルにいるよりも別々なセルにばらけていたほうが良い)
- 未占領領域の隣に自分と相手ユニットがいるとき、ユニット数が多いほど良い
- 重要目標セルへの距離が近いほど良い。それが相手ユニットと同距離のセルであれば相手のユニット数+1のユニット数まで加点。ユニット数負けしているなら2番目に近いユニット数で評価。
- 現在のユニット数と現在matterと将来取得matterでユニットを作成したとき、目安のユニット数に足りない分減点。目安のユニット数は相手とこちらの中間距離のセル数×1.2とした。
- 勝ち確定なら良い。負け確定なら良くない。
その他
行動ループ対応
ゲーム終盤、recyclerもなく相手と自分が同じ行動をし続けることがあります。
相手の毎ターン送り込んでくるユニット数を記録しておき、一定ターン同じ動きが繰り返されていたら、防衛行動の時に相手の行動を前のターンと同じものとしてこちらの行動を決めるようにします。
それでも状況が変わらないなら1ユニットSPAWNして未占領領域をとってまわらせます。
相手陣地に入るときのMOVE
相手陣地への移動を行う時、1マス先の場所を指定してMOVEするようにします。もし移動先にBUILDされても相手陣地に近づくような動きをしてくれます。
場所によっては逆効果なので正確に計算したかったですが、refereeコード移植したのに一致しなくて断念。多分priority_queueの実装がjavaとC++で違うから?
距離や経路の計算にセルの寿命を考慮
距離3だけど2ターン目に壊れるセルがあるから実際は通れないということがあります。寿命を考慮したBFSで正しく距離を計算しました。
勝ち確定BUILD
BUILDすることで勝ちが確定するならBUILDするようにしました。
フローを使って置く場所を計算したけどそんなことしなくても求まるような?
没:初ターン以外のビームサーチ
思ったように動いてくれない。相手の動きを考慮しないと先のターンを探索してもあんまり意味ないかも?
あと評価関数が重くて回数回せないので没に。
初ターンだけ相手の動きの影響のない範囲なら効果があったのでそこだけ残しました。
感想
初めはルールが単純すぎて最適解みたいなものにみんなたどり着いて差がつかなりそうだし、ルール追加あると思ってました。が、行動の自由度が高いことや相手との駆け引きみたいなのもあって単純なゲームではありませんでした……
選択肢が多いのと相手と同時着手ということもあって探索が難しく、1ターンのみルールベース&貪欲になりました。実装量が多いし泥臭いしで結構手が止まることがありましたが、やるんだやるんだ!と気合をいれて何とか実装してました。
(探索書いて省メモリ&高速化を頑張るようなのが好きかも。ルールベースとか評価値考えるのはちょっと億劫になっちゃう)
コンテスト終了1時間ぐらい前にレートがすごく高くなってたので安心してカツ丼を買いに行きました。そしたら終了直前ぐらいに抜かされてしまい……評価値改善とかまだまだやれることはあったはずなのに手を止めてしまったのは良くなかった。
期間が長かったので序盤あんまり集中できていなかった、ゲームを単純だと思い込んでいた、方針決めが遅すぎたとか、良くないところいろいろあったので反省。
次回も頑張る!